We present a series of almost settled inapproximability results for three fundamental problems. The first in our series is the {\em subexponential-time} inapproximability of the {\em maximum independent set} problem, a question studied in the area of {\em parameterized complexity}. The second is the hardness of approximating the {\em maximum induced matching} on bounded-degree bipartite graphs. The last in our series is the tight hardness of approximating the {\em 
- For any
larger than some constant, any
. This nearly matches the upper bound of
[Cygan et al: Manuscript 2008]. It also improves some hardness results in the domain of parameterized complexity (e.g. [Escoffier et al: Manuscript 2012] and [Chitnis et al: Manuscript 2013]).
- For any
-approximation algorithm for the
is the number of vertices in an input graph. This almost matches the upper bound of
(by Balcan and Blum in [Balcan and Blum: Theory of Computing 2007] and an algorithm in this paper).
We note an interesting fact that, in contrast to 

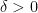
The proofs of our hardness results rely on several unexpectedly tight connections between the three problems. First, we establish a connection between the first and second problems by proving a new graph-theoretic property related to an {\em induced matching number} of dispersers. Then, we show that the
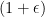 -approximation algorithms for the all-pairs shortest paths problem in unweighted undirected
-approximation algorithms for the all-pairs shortest paths problem in unweighted undirected  -edge graphs under edge deletions. The fastest algorithm for this problem is a randomized algorithm with a total update time of
-edge graphs under edge deletions. The fastest algorithm for this problem is a randomized algorithm with a total update time of 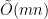 and constant query time by Roditty and Zwick (FOCS 2004). The fastest deterministic algorithm is from a 1981 paper by Even and Shiloach (JACM 1981); it has a total update time of
and constant query time by Roditty and Zwick (FOCS 2004). The fastest deterministic algorithm is from a 1981 paper by Even and Shiloach (JACM 1981); it has a total update time of  and constant query time. We improve these results as follows:
and constant query time. We improve these results as follows: and constant query time that has an additive error of two in addition to the
and constant query time that has an additive error of two in addition to the  . Note that the additive error is unavoidable since, even in the static case, an
. Note that the additive error is unavoidable since, even in the static case, an  -time (a so-called truly subcubic) combinatorial algorithm with
-time (a so-called truly subcubic) combinatorial algorithm with 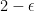 , unless we make a major breakthrough for Boolean matrix multiplication (Dor, Halperin and Zwick FOCS 1996) and many other long-standing problems (Vassilevska Williams and Williams FOCS 2010). The algorithm can also be turned into a
, unless we make a major breakthrough for Boolean matrix multiplication (Dor, Halperin and Zwick FOCS 1996) and many other long-standing problems (Vassilevska Williams and Williams FOCS 2010). The algorithm can also be turned into a 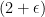 -approximation algorithm (without an additive error) with the same time guarantees, improving the recent
-approximation algorithm (without an additive error) with the same time guarantees, improving the recent  -approximation algorithm with
-approximation algorithm with  running time of Bernstein and Roditty (SODA 2011) in terms of both approximation and time guarantees.
running time of Bernstein and Roditty (SODA 2011) in terms of both approximation and time guarantees. . The algorithm has a multiplicative error of
. The algorithm has a multiplicative error of 